Importance of Apache Spark and Scala in Big Data Industry
Category: Apache spark and scala Posted:Mar 10, 2017 By: Serena Josh Big Data is used over network clusters and used as an essential application in several industries. The broad use of Hadoop and MapReduce technologies shows how such technology is constantly evolving. The increase in the use of Apache Spark, which is a data processing engine, is testament to this fact.
Big Data is used over network clusters and used as an essential application in several industries. The broad use of Hadoop and MapReduce technologies shows how such technology is constantly evolving. The increase in the use of Apache Spark, which is a data processing engine, is testament to this fact.
Introduction to Scala
Scala refers to Scalable Language which means unrestricted abilities which can be used to expand on the lines of your needs. Scala, like Java is an object-oriented language which is general purpose. Scala can be used as a simple scripting language or even as a language for Application of a critical nature.
Capabilities of Scala:
- Functional programming support, with features consisting of pattern matching, immutability, currying, type interference, and lazy evaluation.
- An advanced type system consisting of anonymous types and algebraic data types.
- Features that are not available in Java, like no checked exceptions, operator overloading, raw strings, and named parameters.
- Scala also supports cluster computing, with the most ubiquitous framework solution, Spark, written with Scala. Given Below is the job market for Scala:

Introduction to Apache Spark
Big Data processing frameworks like Apache Spark provides an interface for programming data clusters using fault tolerance and data parallelism. Apache Spark is broadly used for speedy processing of large datasets.
Apache Spark is an open-source platform, built by a broad group of software developers from 200 plus companies. Over 1000 plus developers have contributed since 2009 to Apache Spark.
Superior abilities for Big Data applications are provided by Apache Spark when compared to other Big Data Technologies like MapReduce or Hadoop. The Apache Spark features are as follows:
- Holistic framework
Spark delivers a holistic and integrated framework to manage Big Data processing, and supports a varied range of data sets including batch data, text data, real-time streaming data and graphical data.
- Speed
Spark is able to run programs close to 100 times faster than Hadoop clusters in memory, and over ten times faster when running on disk. Spark has a complex DAG or Directed Acrylic Graph) execution engine that provides support for cyclic data flow and in-memory data sharing across DAGs to carry out different jobs with the same data.
- Easy to use
Spark lets programmers to write Python, Scala, Java, or applications in quick time, with a built-in set of over 80 high-level operators.
- Enhanced support
Spark provides support for streaming data, SQL queries, graphic data processing, and machine learning, in addition to Map and Reduce operations. Given below is a figure displaying why Spark streaming is superior to traditional systems:
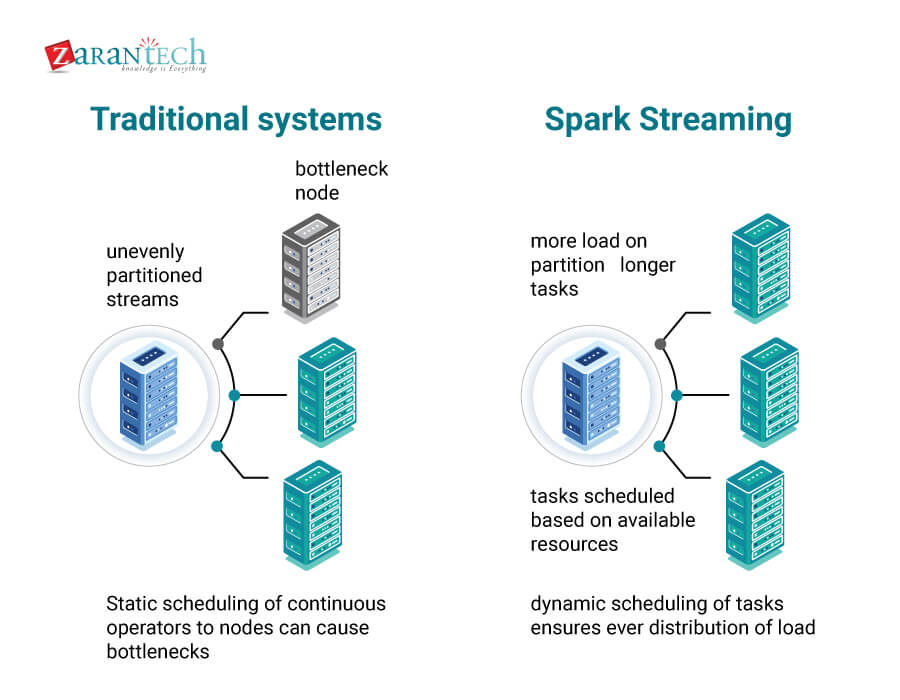
- Inter-platform operability
Apache Spark applications can be run in the cloud or on a standalone cluster mode. Spark provides access to varied data structures including HBase, Tachyon, HDFS, Cassandra, Hive, and any Hadoop data source. Spark can be deployed on a distributed framework such as YARN or Mesos or as a standalone server.
- Flexibility
In addition to Scala programming language, programmers can use Clojure, Java, and Python to build applications using Spark.
- Holistic library support
One can integrate additional libraries within the same application, and give Big Data analytical and Machine learning capabilities as a Spark programmer. The supported libraries range from Spark Streaming and Spark GraphX to Spark SQL.
Compatibility with Hadoop and MapReduce
Apache Spark can be speedier relative to other Big Data technologies.Apache Spark can run on an existing Hadoop Distributed File System or HDFS to provide compatibility along with enhanced functionality. It is simple to deploy Spark applications on existing Hadoop v1 and v2 cluster. HDFS is used for data storage by Spark, and can work with data sources which are compatible with Hadoop including HBase and Cassandra.
Apache Spark is compatible with MapReduce and enhances its capabilities with features such as in-memory data storage and real-time processing.
5 Reasons Why You Should Learn Apache Spark Now
Enterprises throughout the world are generating big data at a highly accelerated speed, leading to the pressing need for such companies to extract meaningful business insights to boost the bottom line.
With a diverse set of alternatives available for Big Data processing such as Storm and Hadoop in the market, Spark is quickly emerging as the next evolutionary step in Big Data environments. This is because it gives streaming as well as batch capabilities turning it into the top choice of platform for faster data analysis. The increase in adoption of Spark over Hadoop and other competitors is almost exponential and increasing in rate. Here are a few great reasons to adopt Spark:
upgrade one’s Big Data skills.
According to the 2015 Data Science Salary Survey by O’Reilly, there exists a strong link between professionals who utilize Spark and Scala and the change in their salaries. The survey has shown that professionals with Apache Spark skills added $11,000 to the median or average salary, while Scala programming language affected an increase of $4000 to the bottom line of a professional’s salary. Apache Spark developers have been known to earn highest average salary among other programmers utilizing ten of the most prominent Hadoop development tools. Real-time big data applications are going mainstream faster and enterprises are generating data at an unforeseen and rapid rate and 2017 is the best time for professionals to learn Apache Spark online and help companies progress in complex data analysis. Here are some interesting facts in a figure about Scala:

Developers who have harnessed Hadoop for distributed data analytics are now tapping into big data with Apache Spark framework as it enables in-memory computing – rendering performance benefits to users over Hadoop’s cluster storage approach. Spark distributes and caches data in-memory and is a big hit among data scientists as it helps them write fast machine learning algorithms on large data sets. Apache Spark is executed in Scala programming language that acts as an excellent platform for data processing. Apache Spark in one of the fastest growing big data community with more than 750 contributors from 200 plus enterprises worldwide.
Get More Insights about Apache Spark(Attend Free Webinar)
5 Reasons to Learn Apache Spark
1) Apache Spark leads to Increased Access to Big Data
Enterprises are being presented with a diverse set of opportunities by Apache spark in terms of Big Data exploration in order to solve Big Data problems. With Spark being highly in demand and it being the most desired piece of tech in the current market, both data scientists and data engineers have chosen by and large to work with Spark. An astounding platform for data scientists, Spark has use cases and scenarios that span across various operational and investigative analytics.
Apache Spark has the unique and distinct feature of storing data which is resident in-memory and this greatly helps in speeding up machine learning workloads which is very much unlike MapReduce and Hadoop. IBM’s bold initiative states that it is aiming at educating more than a million data engineers and scientists from the year 2016.
2) Apache Spark Makes Use of Existing Big Data Investments
After Hadoop came along, most enterprises took to computing clusters to take advantage of the technology. With the advent of Apache Spark there are no restrictions or limitations that have to be considered since Spark can be utilized atop the existing Hadoop clusters.
Spark is able to run MapReduce since it is able to run on HDFS and YARN. Since Spark is highly compatible with Hadoop, enterprises are poised to hire an increasing number of Spark developers since there is no re-investment because it can be integrated with Hadoop without problems. This means Spark skills are highly transferable. The figure sown below shows that the Spark query Run time using Scala is the shortest, leading to conclude that Scala is the most efficient compared to its competitors.
3) Apache Spark helps keep pace with Growing Enterprise Adoption
Corporations are now adopting multiple Big Data technologies that complement Hadoop and Spark adoption. Spark is not just an element of the Big Data Hadoop Ecosystem but it has turned into the most needed and in-demand Big Data technology for businesses across multiple verticals.
Spark adoption has seen the Spark community contribute the most, relative to other open source projects which are handled by the Apache foundation. The demand to support BI workloads using a mix of Spark SQL and Hadoop is rising steadily in the current market scenario. The figure below relating to running time of Hadoop and Spark clearly shows Spark as the faster option:
International survey findings have shown that among companies that adopt Apache Spark 68% of the companies are using Spark to provide support for BI workloads. Spark’s undisputed value proposition is leading to a boosted adoption rate by enterprises opening up highly profitable opportunities for big data developers with Spark and Hadoop skills.
4) Learn Apache Spark as 2017 is set to witness an increasing demand for Spark Developers
Spark’s enterprise adoption is rising as it is being regarded as being the smarter alternative to Hadoop’s MapReduce – within the Hadoop framework or even outside of it. Similar to Hadoop, Apache Spark also needs technical expertise in object oriented programming concepts both to program and run- therefore opening up jobs for those who have hands-on working experience in Spark. Throughout the IT industry there is a widespread shortage in professionals with Spark Skillsets leading to a large number of vacancies for Big Data professionals for permanent as well as contractual positions.
Professionals can leverage this clear skillset gap by undergoing a certification in Apache Spark.
5) Apache Spark clears the path to amazing pay packages
Since Spark developers are greatly in demand, enterprises are even willing to make exceptions in the recruitment processes and extending them to offer considerable incentives and benefits that include flexible work timings. As of March 7, 2017 the average salary for an Apache Spark Developer in San Francisco is $133,021 per annum which is around 29% above the national average.

Conclusion:
As Spark continues to be used for interactive scale out data processing requirements and batch oriented needs, it is expected to play a vital role in the next generation scale-out BI applications. Professionals would be wise to take on holistic hands-on training in Spark to boost productivity which is especially true if they are new to Scala programming. This needs professionals to get familiar with a new programming platform like Scala. However, one can also use Shark or SQL on Shark to begin learning Apache Spark. Developers can also code in Python, Java, R (Spark) to design analytics workflows in Spark.
Apache Spark framework’s standard API makes it the top pick for Big Data processing and data analytics. For client installation setups of MapReduce implementation with Spark, Hadoop, and MapReduce can be used in tandem for better results.
Apache Spark is found to be a great alternative to MapReduce for installations that include massive quanta of data that need low latency processing. All in all Apache Spark and Scala show great promise in the way they are shaping the IT industry and all industries related to it therein. If you are planning to take up an Apache Certification, then there can’t be a better time than right now!




 99999999 (Toll Free)
99999999 (Toll Free)  +91 9999999
+91 9999999